
Where does this image come from?
The image in question was generated using an open-source AI model: Stable diffusion. As well as being open source, it is licensed under the Open RAIL licence, which allows the model to be reused and modified for commercial purposes. This is precisely the model on which the krea.ai website is based. (KREA - AI Creative Tool - image generations and prompts) which generates images from a prompt, like midjourney or DALL-E.
So far, it's nothing new, as several sites have been appearing since the summer of 2022 to allow you to generate original images from prompts. What's more, by June 2023 a slew of QRs generated with stable broadcasting had already hit the web.

(hugging face)
What's new here is that, in addition to the prompt, you can choose a pattern to make it stand out in your newly generated image. This new feature offered by Krea.ia is called krea.ai/tool/patterns
For example, how to generate "Hello" in the middle of a magnificent Greek landscape:
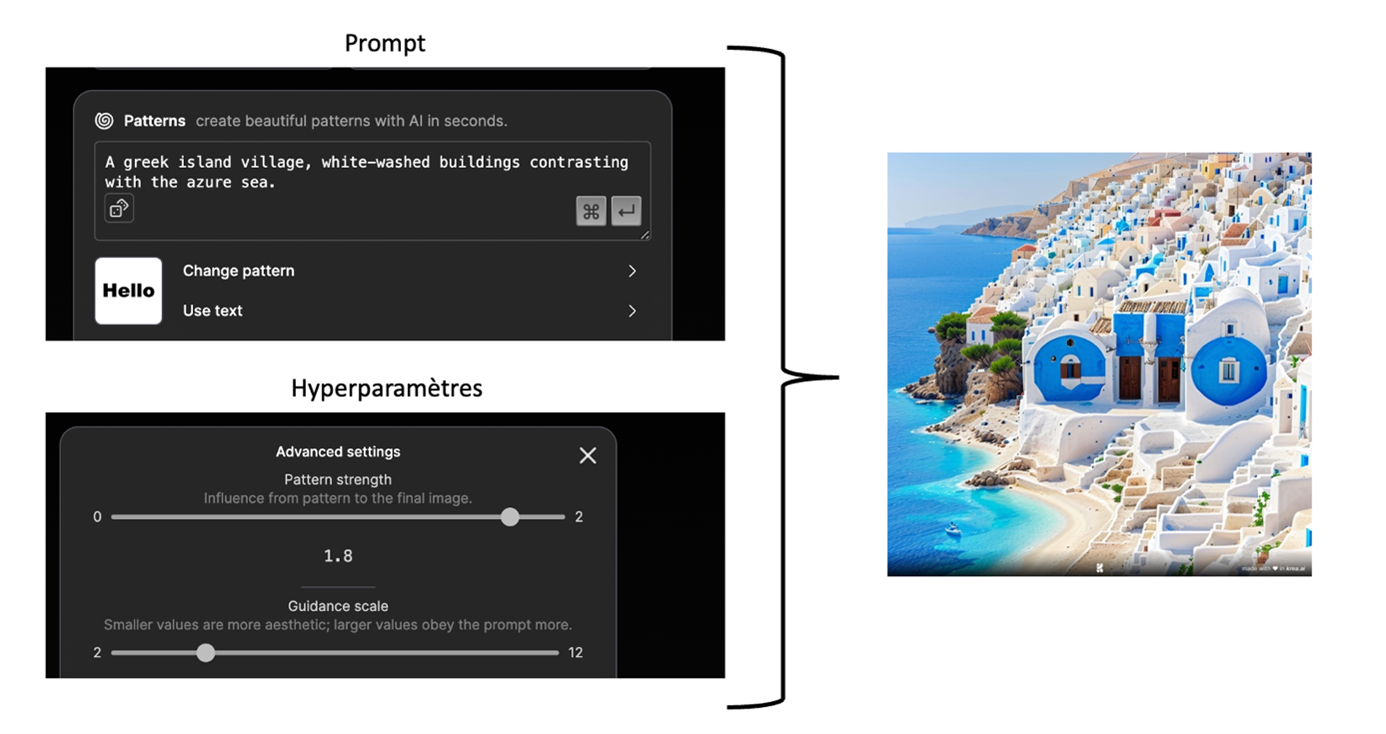
As is often the case with these generative tools, it takes a few tries before you get a satisfactory result. In this example, there are two elements to play with. The first is prompt, which defines the landscape or environment in which you want to display your text. The second element to adjust concerns the hyperparameters. These allow the text to be highlighted or minimised. There are no hard and fast rules for this stage; you need to experiment with different values until you get a satisfactory result.
In the previous image, the word "Hello" is clearly visible, but if you zoom in, the integration of the letters is more "natural". This feat is made possible by Stable Diffusion.

How does this generative platforms work?
Stable Diffusion is a multimodal AI model, meaning that several data sources (e.g. video, image, sound) are processed and combined to solve complex problems. In the case of Stable Diffusion, both images and text are used to generate images.
This model offers two distinct options for its use. The first option is to generate images from text only. In this scenario, the user provides a text input (called a prompt), and the template generates an image in response to this request. The second option is somewhat different, as it focuses on generating a modified version of an existing image. To do this, the user enters a prompt and provides an image to be altered.
Stable Diffusion does not consist of a single template, but is made up of a set of complex templates. In this article, we decompose this model into two main components, which we will explore throughout our discussion:
- The model for understanding a prompt (the user's query) by an AI model.
- The model of image generation from the prompt, through the principle of information diffusion.
By examining these essential components of Stable Diffusion, we will gain a better understanding of how this model works and its impressive image generation capabilities.
1. Representing a text query
The essential aim of neural networks dedicated to text representation is to convert textual content into a digital form suitable for analysis by artificial intelligence models. This transformation is achieved by transposing tokens into a multi-dimensional vector space. To simplify, we can imagine this space as a place where each word in the text is translated into a point in a two-dimensional space (see Figure 1).
-
Figure 1 - Example of the representation of words in a two-dimensional vector space
In this space, we can discern semantic links between words. The closer the words are, the more similar their meanings. In the example, we can see that the words "ecology", "environment" and "sustainable" are closely related, while the word "chair" is far removed. This allows us to visualise themes, such as the theme of the environment in the example given. This mechanism is extremely powerful, as it allows us to recognise that different reformulations of the same sentence (via synonyms, for example) are similar. As a result, the user's prompt is represented with a high degree of accuracy, taking into account the semantics of the words that make it up.
The Stable Diffusion text representation model is based on the use of CLIP [2], a model from the GPT family developed by OpenAI in its current version. This model belongs to the famous family of Transformer models [3], which have enjoyed great popularity since their introduction in 2017.
The training of CLIP is of particular interest, as it aims to associate text and images to assess their similarity. The model is trained with pairs consisting of images and captions, whether or not they are associated with the image in question. Figure 2 shows an example of training this model.

Figure 2 - CLIP model training example
In its new version 2.0, the Stable Diffusion model presents robust models that have been learned using a new text-to-image technology called OpenCLIP. This advance, developed by LAION with the support of Stability AI, has significantly improved the quality of the images generated compared with previous versions.
2. The diffusion mechanism
Diffusion models are key to understanding how Stable Diffusion works. The idea is simple: starting with a noisy image, we want to add more and more information to represent a final image.
The principle of diffusion for image generation is based on the use of powerful computer vision models. Nowadays, given a large enough dataset, these models can learn to perform complex tasks. Diffusion models approach image generation as follows:
Imagine we have a starting image. We generate some noise and add it to this image. This new image is different from the starting image, and can therefore be added to the training set. We repeat this operation many times, with different noise levels, to create many training examples to form the main component of our training model. With this data set, we can learn an efficient noise prediction model that is capable of generating images when run in a specific configuration.

Figure 3 - Example of image generation from noise [1]
Figure 3 illustrates that adding noise to an image creates diversity through the variation in noise, leading to the generation of a whole new set of images. The authors of this figure have used a different model to that used in Stable Diffusion to restore these images to their initial, noise-free state. However, the fundamental principle remains unchanged. Increasing the amount of noise added to an image leads to a diversification of the images generated, and this phenomenon occurs at different noise intensities.
The UNet model was developed to predict and progressively reduce the noise present in an image. This model is very popular because it is able to incorporate text data supplied by the user at each stage of the denoising process. As a result, noise reduction is guided by the user's request at each stage.
In summary, the diffusion method involves a gradual process of adding noise to an existing image in order to generate training examples. Based on these examples, a model can learn to produce high-quality images by applying the right type and amount of noise to a given image.
3. Conclusion
The Stable Diffusion model is complex because it combines several data sources, namely images and text. In addition, it integrates several models, which enables it to achieve high performance in the generation of images from text (and from a combination of text and image). Many other concepts are involved in the construction of this model, but we believe they are easier to understand once the main mechanisms have been explained.
What's the perspectives?
Generative Artificial Intelligence technologies are radically transforming various fields of activity and raising a number of questions, particularly as regards their legal regulation. (Loi sur l'IA de l'UE : première réglementation de l'intelligence artificielle | Actualité | Parlement européen (europa.eu)).
In this context, the approach adopted by Krea.ia with "Stable Diffusion" stands out. This method offers significant potential for boosting communication and marketing strategies. It allows brand logos to be integrated directly into the images, providing an opportunity to amplify and personalise the messages sent to the target audience.
However, generating high-quality visuals using these technologies is no mean feat. It requires a thorough mastery of a number of elements: the judicious choice of model, the precise formulation of the prompt, and the optimal adjustment of hyper-parameters.
Beyond its applications in the artistic and marketing fields, this technology also offers opportunities in the data visualisation (or dataviz) sector. By using generative AI, it is possible to design more impactful graphical representations of data, reinforcing the message of the information presented.

We hope this note has helped you discover a few things about image generation and the possibilities offered by these platforms.
Editors:
Alexandra BENAMAR - PhD in Computer Science
Damien JACOB - PhD in Applied Physics
Sources:
[1] Xiao, Z., Kreis, K., & Vahdat, A. (2021). Tackling the generative learning trilemma with denoising diffusion gans. arXiv preprint arXiv:2112.07804.
[2] Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., ... & Sutskever, I. (2021, July). Learning transferable visual models from natural language supervision. In International conference on machine learning (pp. 8748-8763). PMLR.
[3] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., ... & Polosukhin, I. (2017). Attention is all you need. Advances in neural information processing systems, 30.